Active Learning Core Concepts
Late 2024 — Query Strategies on Forest Covertype Dataset
Why Active Learning?
In traditional ML, labeled data is a prerequisite — but obtaining labels is expensive, especially in domains like healthcare or NLP. Active learning strategically selects the most informative data points for labeling, significantly reducing the amount of labeled data needed while maintaining or improving model performance.
View on GitHub →Dataset: Forest Covertype
The Forest Covertype Dataset contains cartographic features to predict forest cover types. Visualized in 2D using PCA.
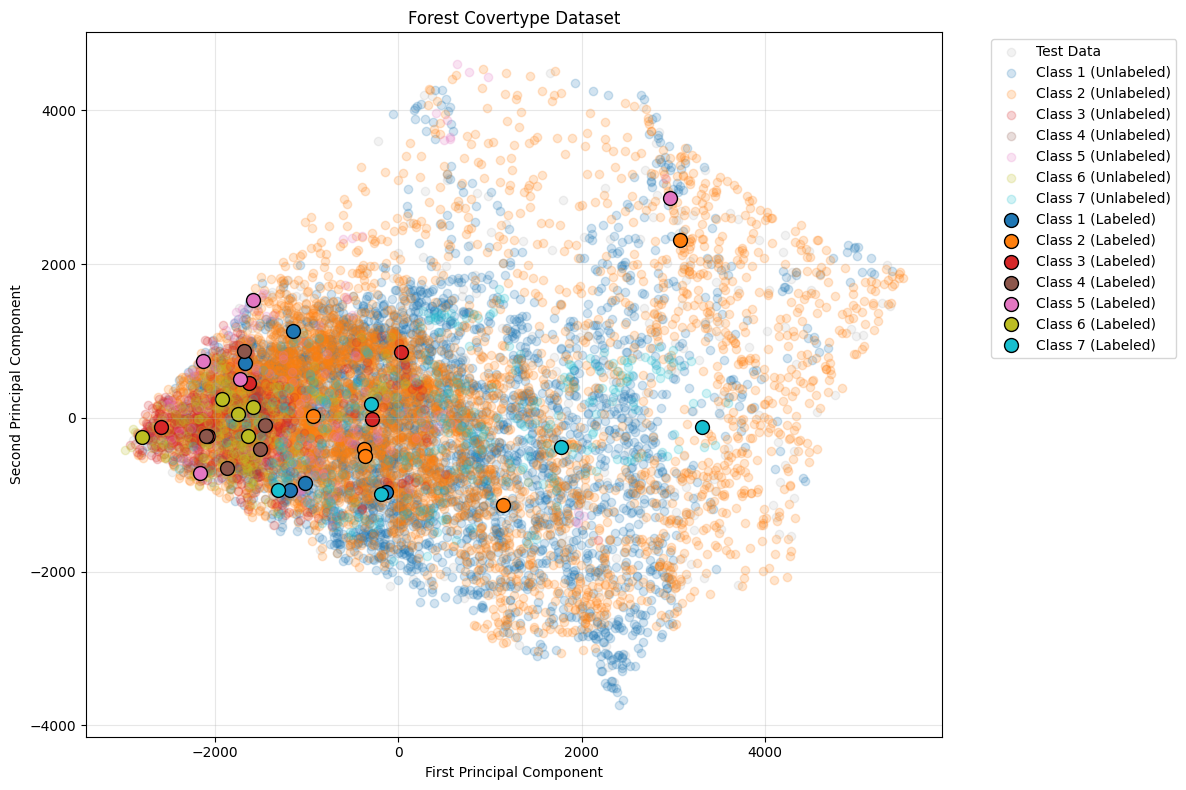
11,000
Total samples
10,000
Training
35
Initial labels
9,965
Unlabeled pool
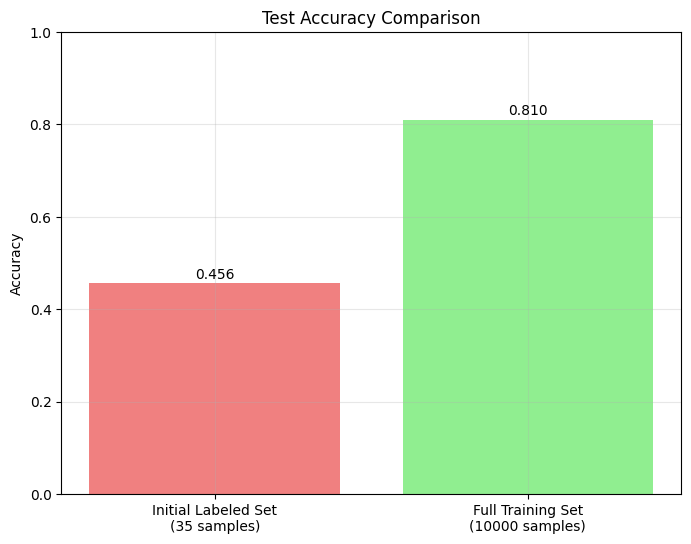
The Performance Gap
Comparing model performance with minimal labels (35 samples) vs. full training data (10,000 samples) highlights the opportunity for active learning.
Query Strategies Compared
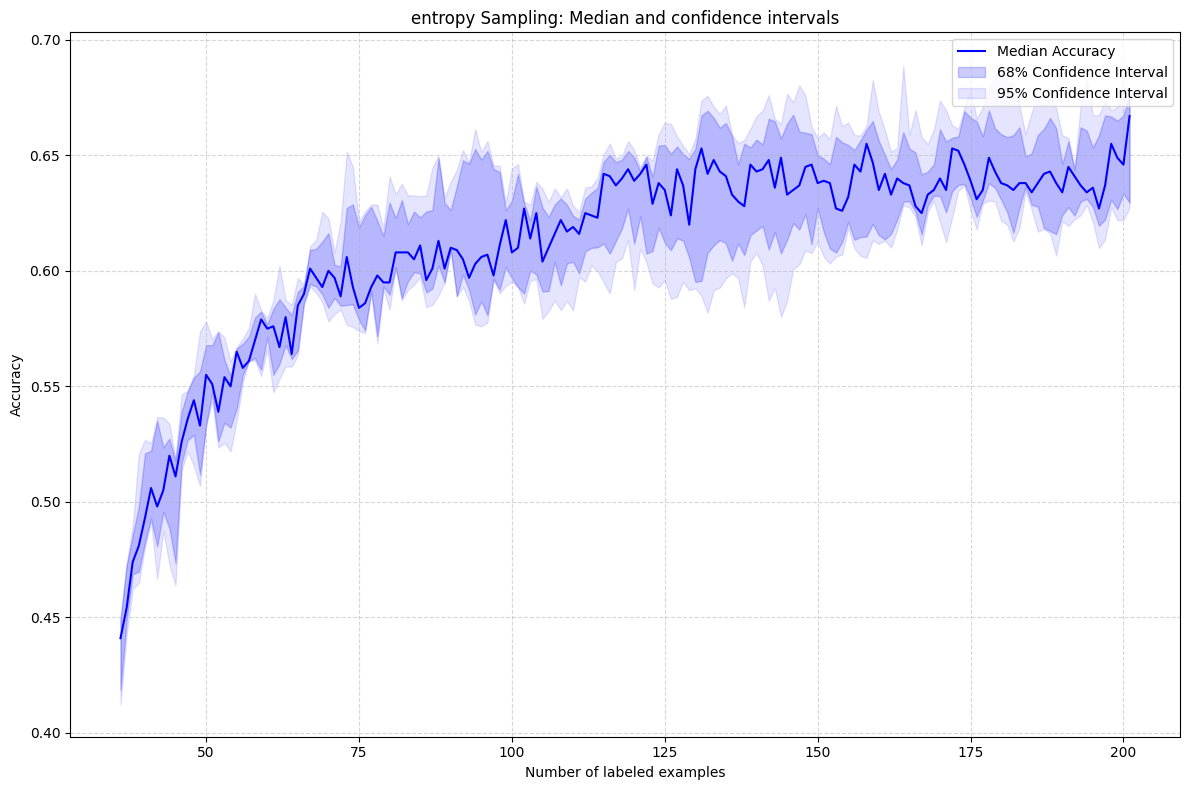
Uncertainty Sampling
- • Least Confident: Lowest max probability
- • Margin: Smallest gap between top-2 classes
- • Entropy: Highest information-theoretic uncertainty
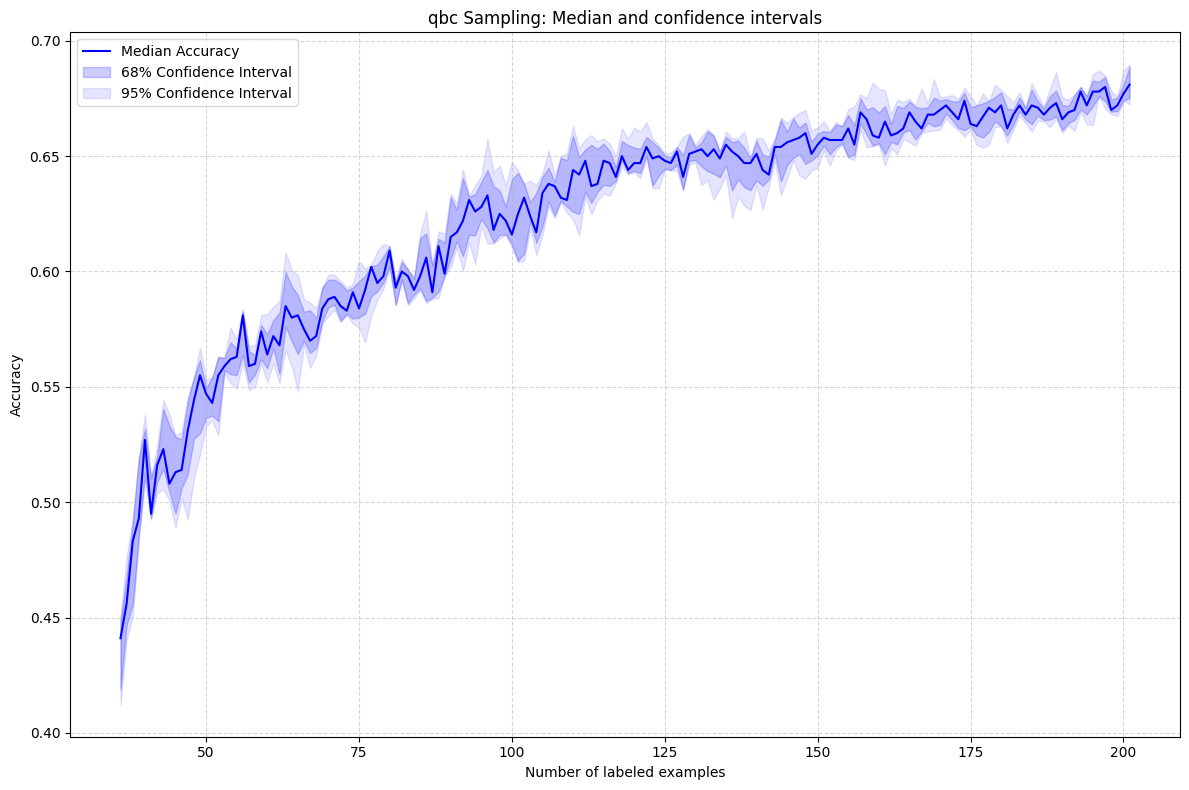
Query-by-Committee (QBC)
Measures disagreement among an ensemble of models trained on bootstrapped subsets.
Query-by-Committee (QBC)
Entropy Sampling
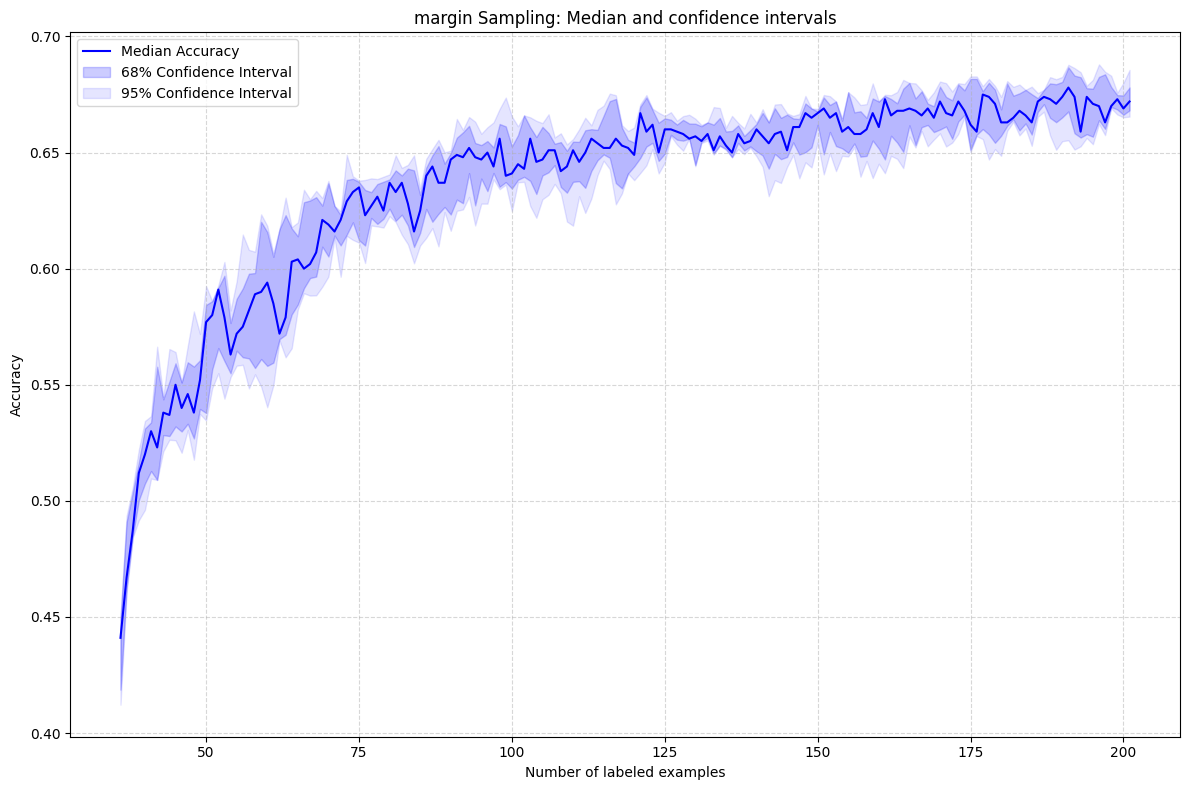
Margin Sampling
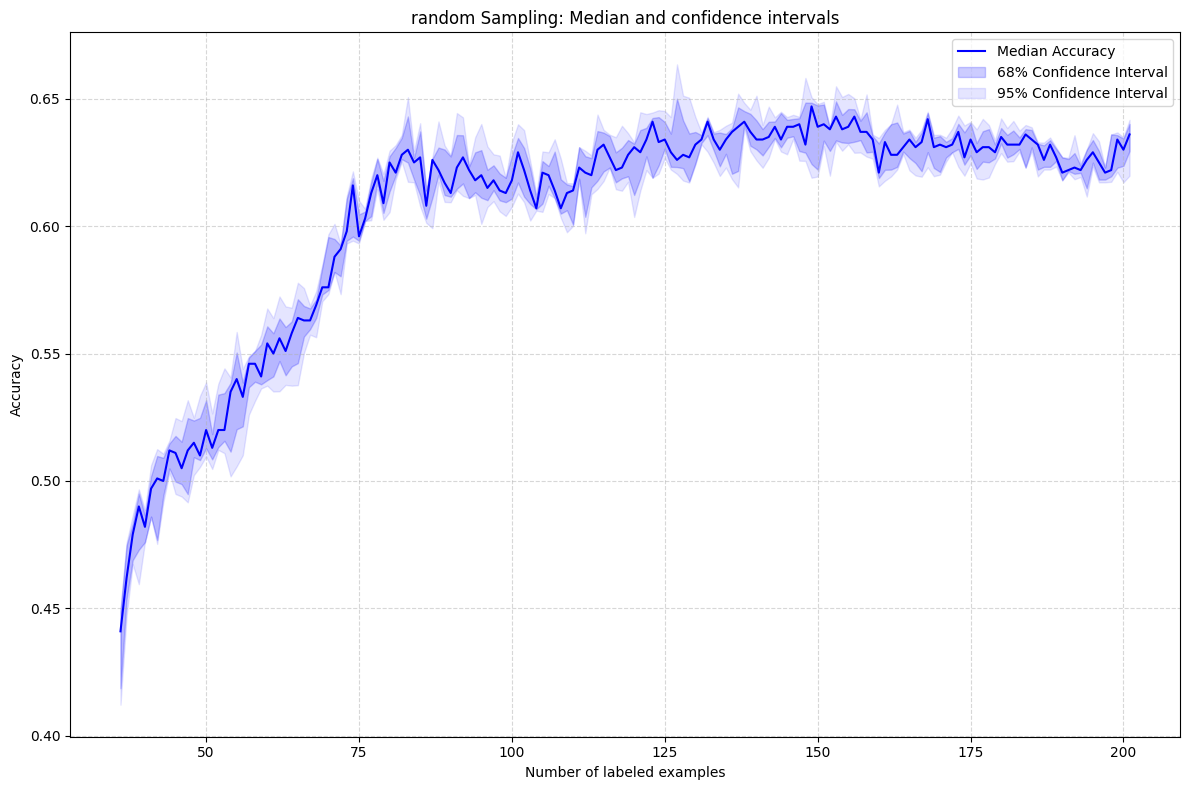
Random Sampling (Baseline)
All Strategies Combined
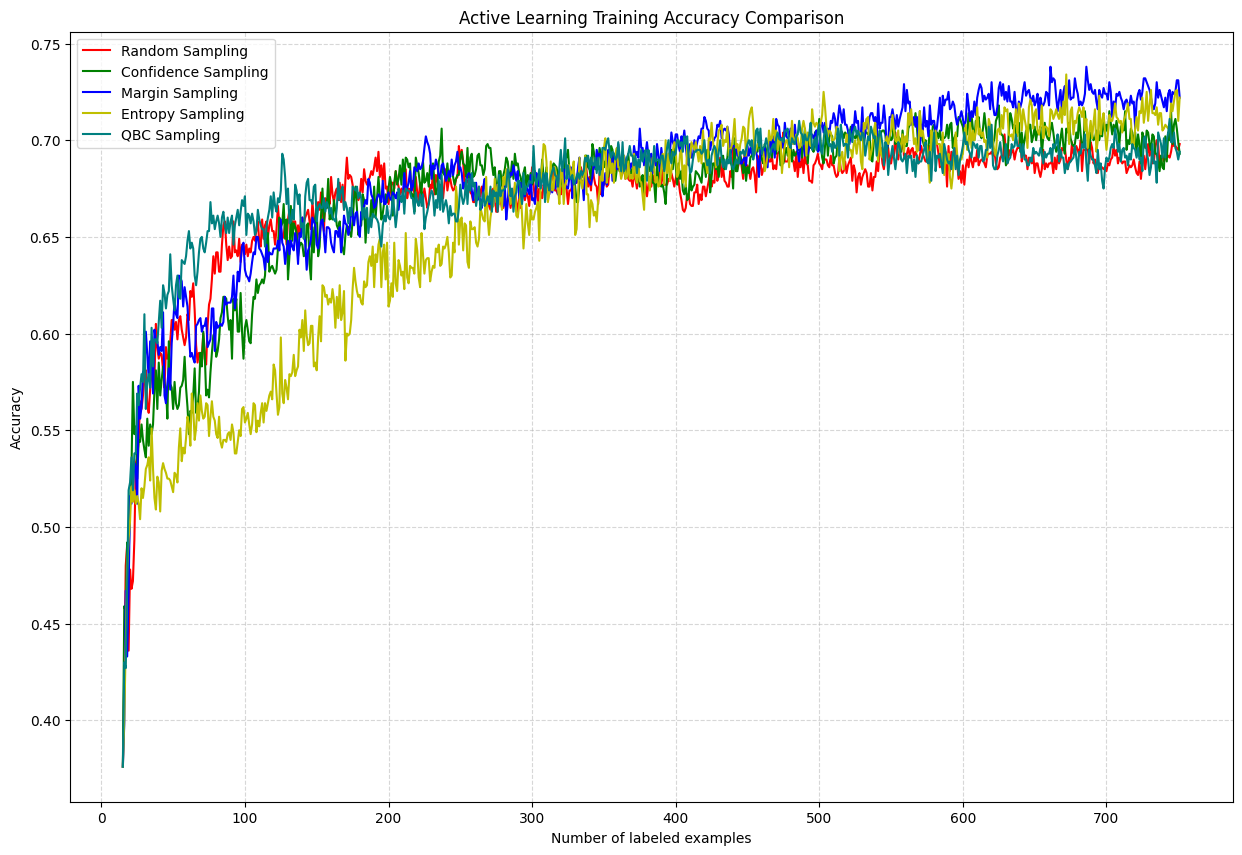
Observations:
- 🥇 QBC & Entropy: Best early-stage performance, minimizing labeling cost
- 🥈 Margin Sampling: Competitive but slightly less robust
- 🥉 Random: Baseline, least improvement over time
- 📊 Variance: QBC shows slightly more variance (committee-based approach)
Key Takeaways
- ✅ Active learning works — reaches near-full-data performance with far fewer labels
- ✅ QBC and Entropy are most effective in early stages
- ✅ Confidence intervals help assess strategy robustness
- ✅ Real-world impact: Reduces labeling costs in expensive domains