Bayesian Deep Active Learning
Late 2024 — Active Learning with Uncertainty Quantification
About
Implementations and analyses of active learning experiments using Bayesian neural networks (BNNs) with MC Dropout. The experiments span MNIST and Dirty-MNIST datasets, investigating different acquisition strategies including Random Sampling, Margin Sampling, and BALD (Bayesian Active Learning by Disagreement).
View on GitHub →MNIST Experiments
1. Setup: Training a BNN with MC Dropout
First step was training a Bayesian Neural Network on the full MNIST training dataset, evaluating test accuracy and Negative Log-Likelihood (NLL).
Final Results (Epoch 10/10):
97.25%
Train Accuracy
98.74%
Test Accuracy
0.0943
Train NLL
0.0667
Test NLL
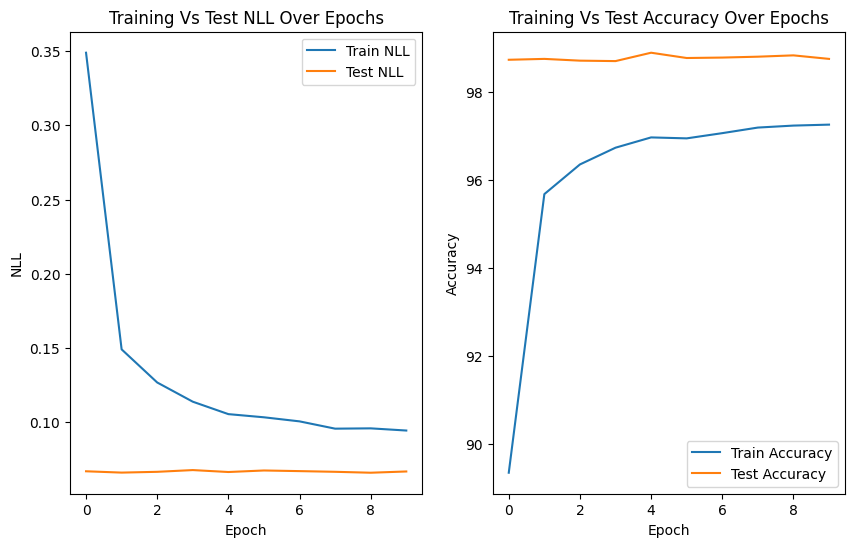
Training and test curves for NLL and accuracy over 10 epochs
2. Baseline: Random Acquisition
Active learning with random acquisition starting with 2 labeled examples per class (20 total), acquiring batches of K=10 samples until reaching 1020 total labeled examples. Averaged over 10 trials.
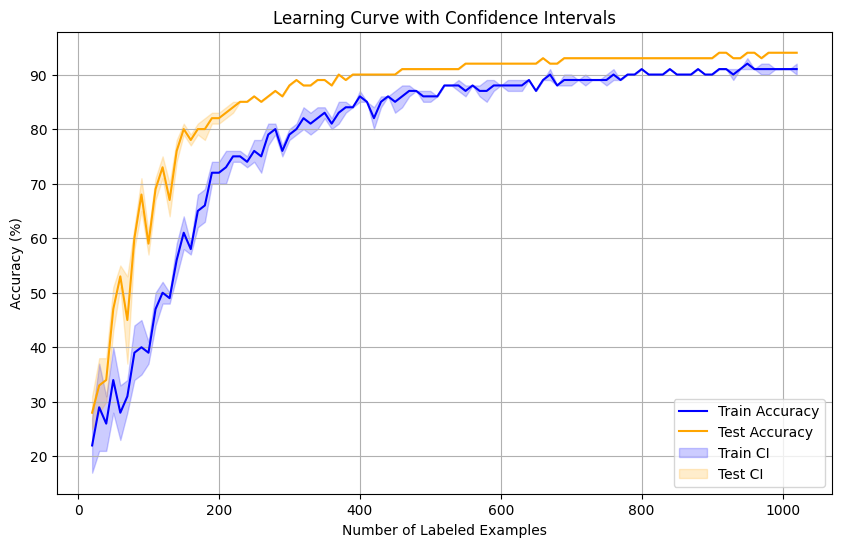
Learning curve with confidence intervals — accuracy improves rapidly initially
3. Scaling Behavior: Epochs vs. Labeled Data
Exploring trade-offs between training longer (more epochs) vs. acquiring more labeled data.
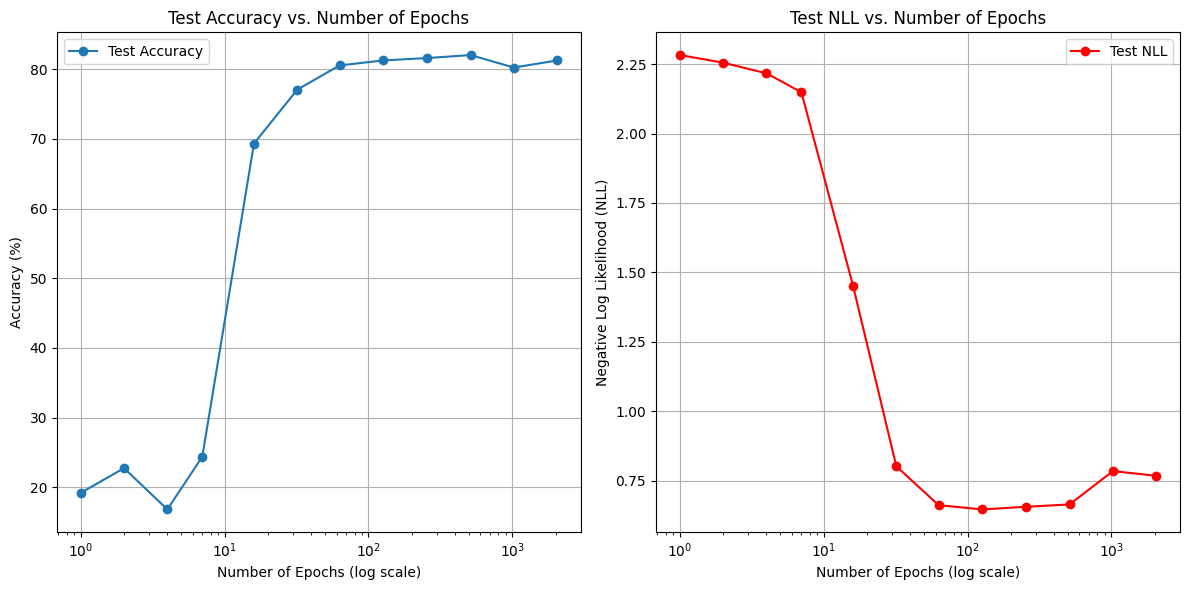
Fixed 5 labels/class, varying epochs (1→2048)
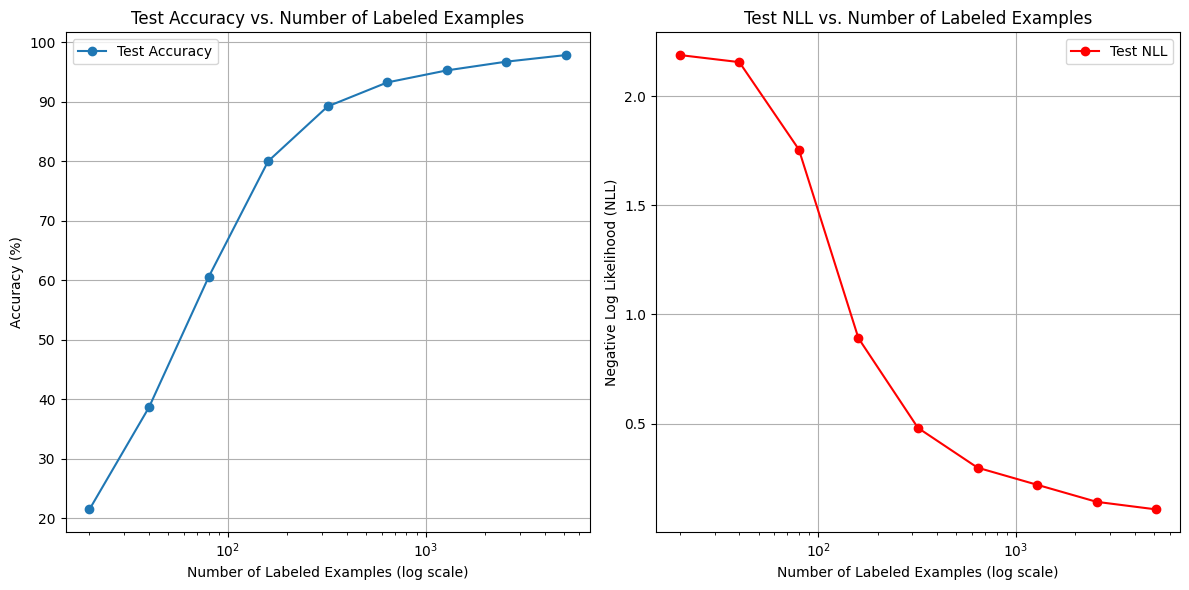
Fixed 10 epochs, varying labels (2→512/class)
Key Insight: More labeled examples generally outperform longer training epochs for improving accuracy and reducing NLL.
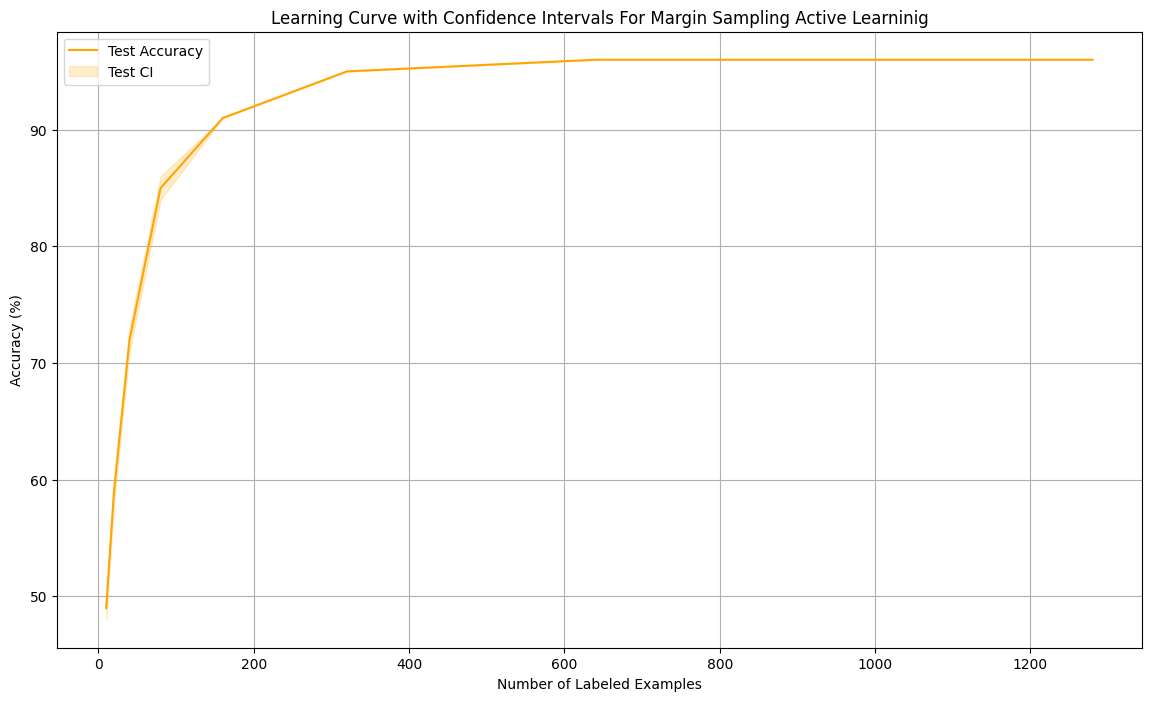
4. Margin Sampling
Selects samples with the smallest difference between the two most probable predicted classes — prioritizing where the model is most uncertain.
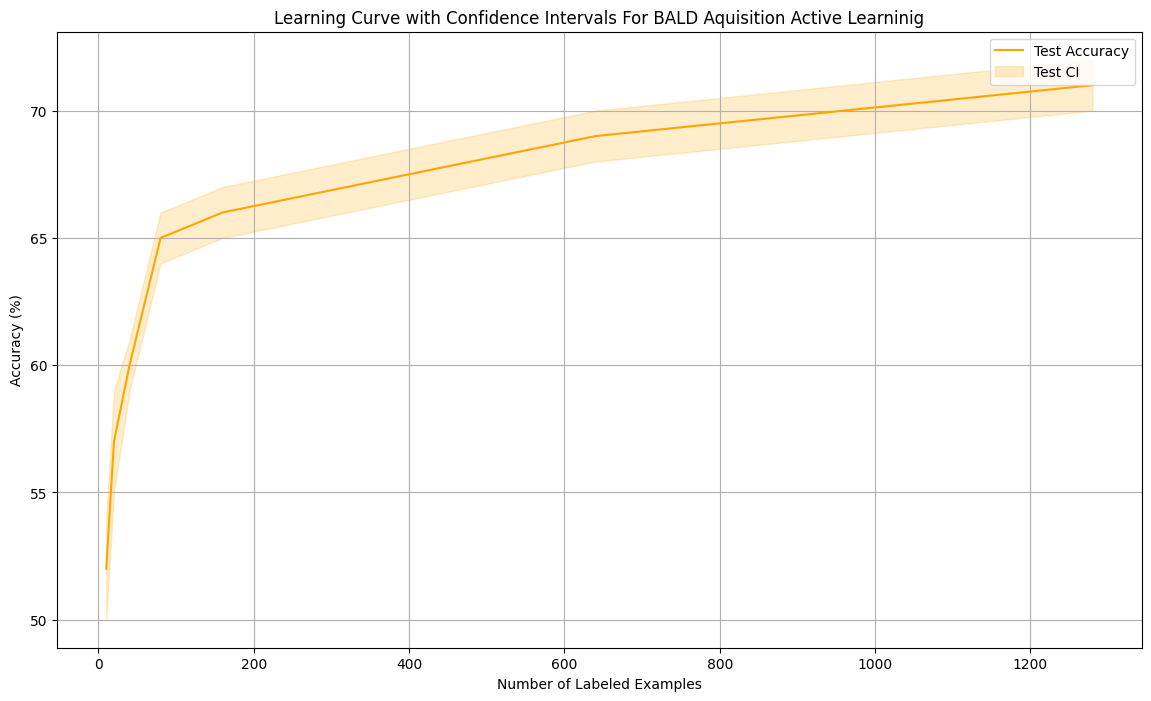
5. BALD (Bayesian Active Learning by Disagreement)
Bayesian acquisition strategy that selects samples with high epistemic uncertainty — quantifying disagreement among the ensemble of models.
All Strategies Compared
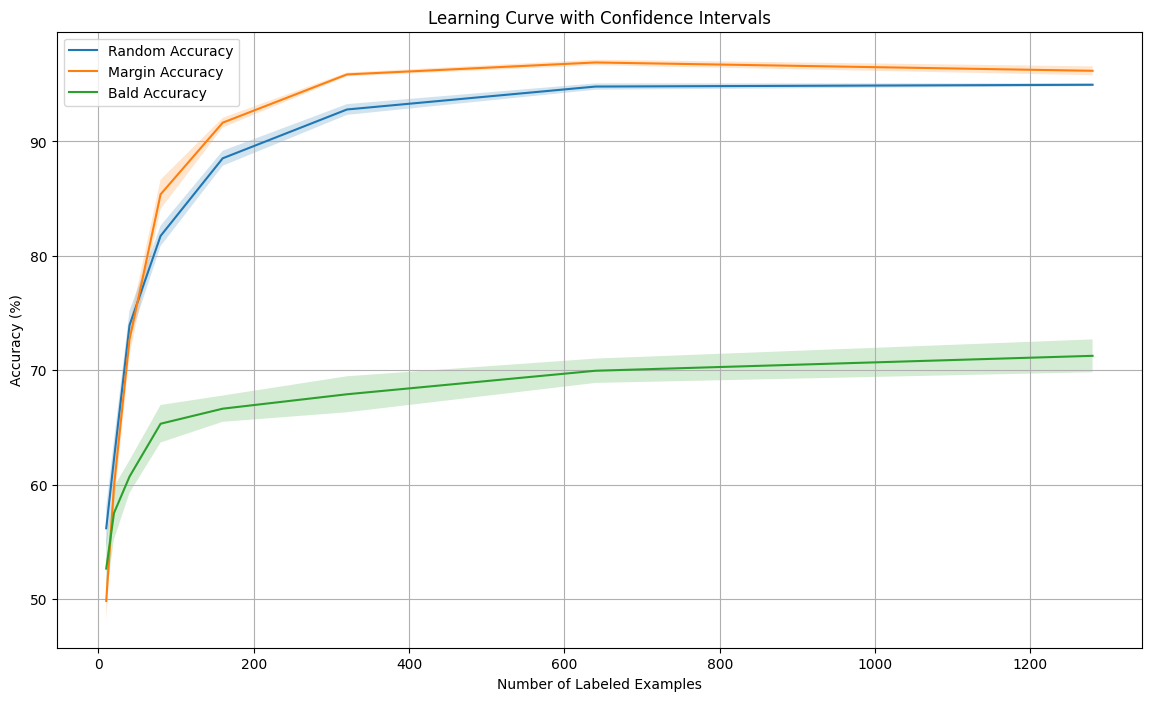
Results Summary:
- 🥇 Margin Sampling: Best accuracy, convergence speed, and stability
- 🥈 Random Acquisition: Reasonable baseline performance
- 🥉 BALD: Slower convergence but valuable for understanding uncertainty
6. Top-K Trade-Offs for BALD
Comparing individual sample acquisition (K=1) vs batch acquisition (K=10) in BALD.
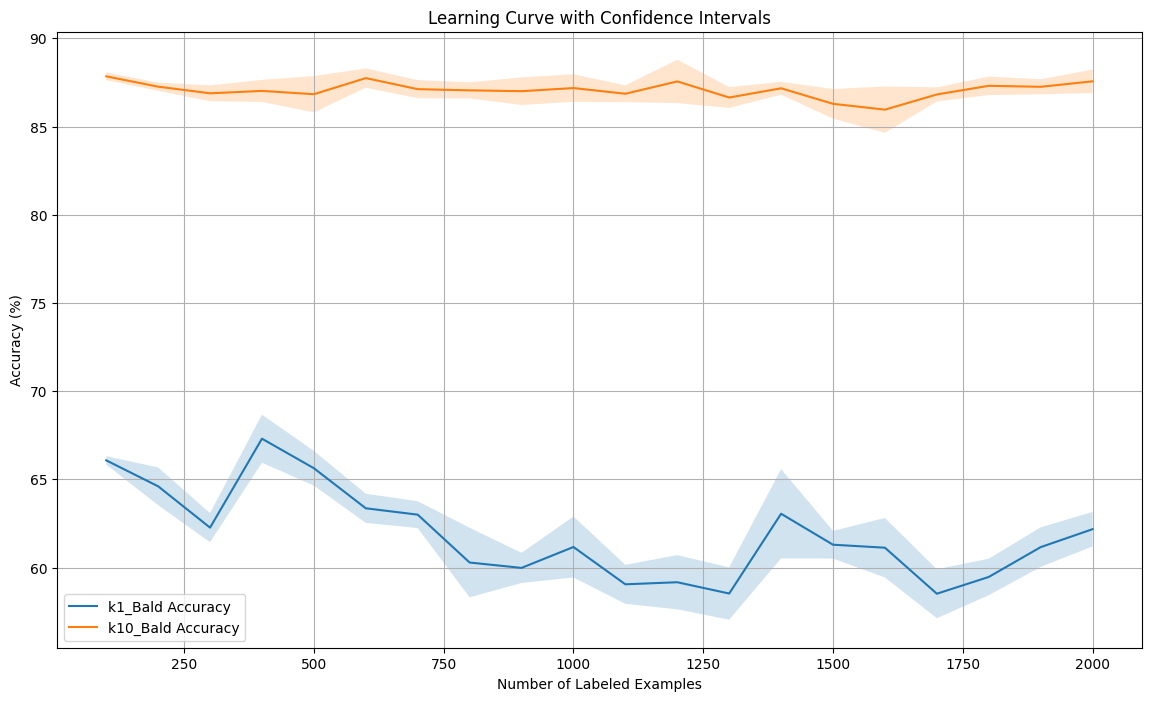
K=10 shows more stable learning with faster convergence
Dirty-MNIST Experiments
Evaluating acquisition strategies on the noisy Dirty-MNIST dataset — testing robustness to noise.
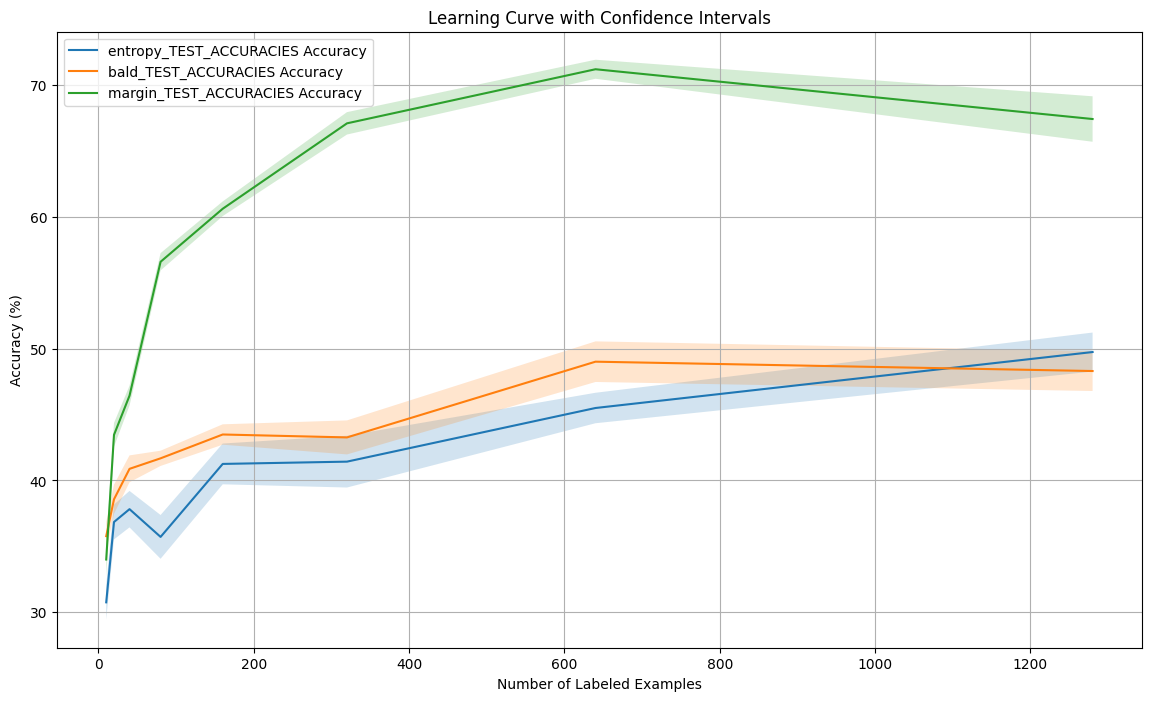
Key Finding: Margin Sampling is most robust to noise, outperforming BALD and Entropy-based acquisition on noisy data.
Key Takeaways
- ✅ Margin Sampling wins — most effective for both clean and noisy datasets
- ✅ More data beats more epochs — acquiring labels is more valuable than training longer
- ✅ Batch acquisition (K=10) is more practical than single-sample (K=1)
- ✅ BALD provides uncertainty insights but has computational overhead