🎮
AIMS Coursework
DQN — CartPole
Late 2024 — Deep Q-Network with Experience Replay
DQN
Q-Learning
Replay Buffer
Target Network
About
Implementation of Deep Q-Network to solve the classic CartPole environment. The agent learns to balance a pole on a cart using Q-learning with neural network function approximation, epsilon-greedy exploration, experience replay, and target networks.
View on GitHub →Environment: CartPole-v1
4
State dims
2
Actions
500
Max reward
+1
Per timestep
State: cart position, cart velocity, pole angle, pole angular velocity
Method: Deep Q-Network
Neural Network
- • Input: 4-dim state vector
- • 2 hidden layers × 20 units
- • Output: 2 Q-values (left/right)
Key Components
- • Replay buffer (10K transitions)
- • Target network (stable targets)
- • Epsilon-greedy exploration
Hyperparameters:
LR: 3e-4
Batch: 512
γ: 0.99
ε decay: 3000 steps
Results
✅ Solved! Agent achieves maximum reward (500) after ~800 episodes
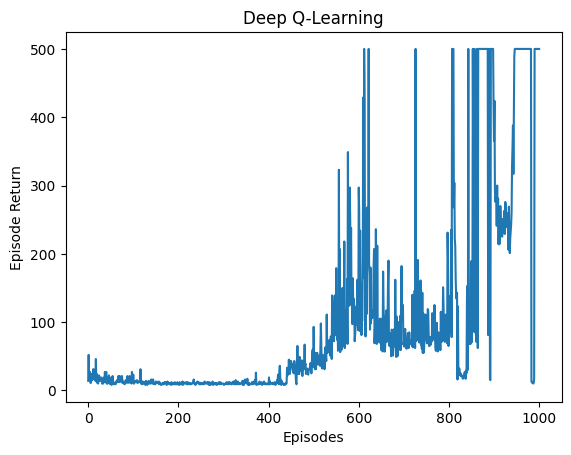
Episode returns over training — steady improvement to max reward
Key Observations
- ✅ Convergence — Agent consistently achieves maximum reward
- ✅ Epsilon-greedy ensures adequate exploration initially
- ✅ Replay buffer significantly stabilizes training
- ✅ Target network reduces instability from bootstrapping