🚀
AIMS Coursework
DQN — LunarLander
Late 2024 — Deep Q-Network for Complex Control
DQN
LunarLander-v2
8-dim state
4 actions
About
Extending DQN to the more challenging LunarLander-v2 environment. The agent must navigate and land safely on a target pad, managing thrust in multiple directions with an 8-dimensional state space.
View on GitHub →Environment: LunarLander-v2
8
State dims
4
Actions
250+
Target return
-380
Initial return
Actions: do nothing, fire left engine, fire main engine, fire right engine
Key Modifications from CartPole
- • Batch Size: 128 (was 512) for efficient training
- • Buffer Size: 15,000 (was 10,000) for sample diversity
- • Epsilon Decay: 10,000 steps (was 3,000) for thorough exploration
- • Min Epsilon: 0.15 (was 0.1) for continued exploration
- • Learning Rate: 1e-3 (was 3e-4)
Results
-380
Initial Performance
250+
Final Performance (670 eps)
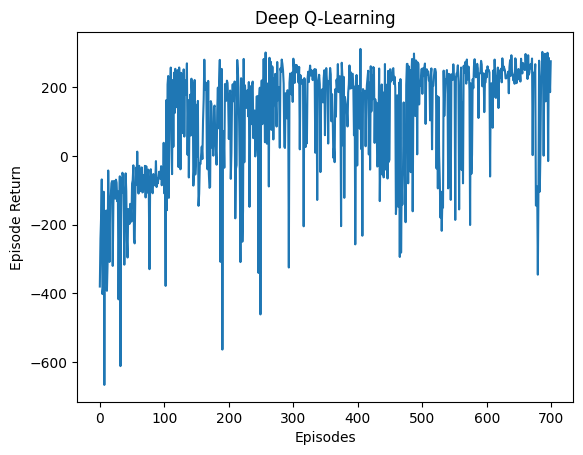
Training curve showing improvement from -380 to 250+ over 700 episodes
Key Observations
- ✅ Extended epsilon decay crucial for exploring diverse landing strategies
- ✅ Larger buffer provides more diverse training samples
- ✅ Replay buffer + target network significantly stabilize training
- ✅ More complex environment requires careful hyperparameter tuning