🌙
AIMS Coursework
REINFORCE — LunarLander
Late 2024 — Policy Gradient for Complex Control
Policy Gradient
REINFORCE
LunarLander-v2
5000+ episodes
About
Applying the REINFORCE policy gradient algorithm to the challenging LunarLander-v2 environment. The agent must learn to control thrust in multiple directions to safely land on the target pad using only episodic returns for learning.
View on GitHub →Environment: LunarLander-v2
8
State dims
4
Actions
5000+
Episodes
128
Batch size
Implementation Details
Key Components
- • Policy Network: FC network outputting action logits
- • Returns Calculation: Discounted Monte Carlo returns
- • Loss: Log-probability weighted by returns
- • Optimizer: Adam with learning rate adjustments
Challenge: LunarLander is harder than CartPole for REINFORCE due to sparse rewards and longer episodes. Required 5000+ episodes vs ~2500 for CartPole.
Results
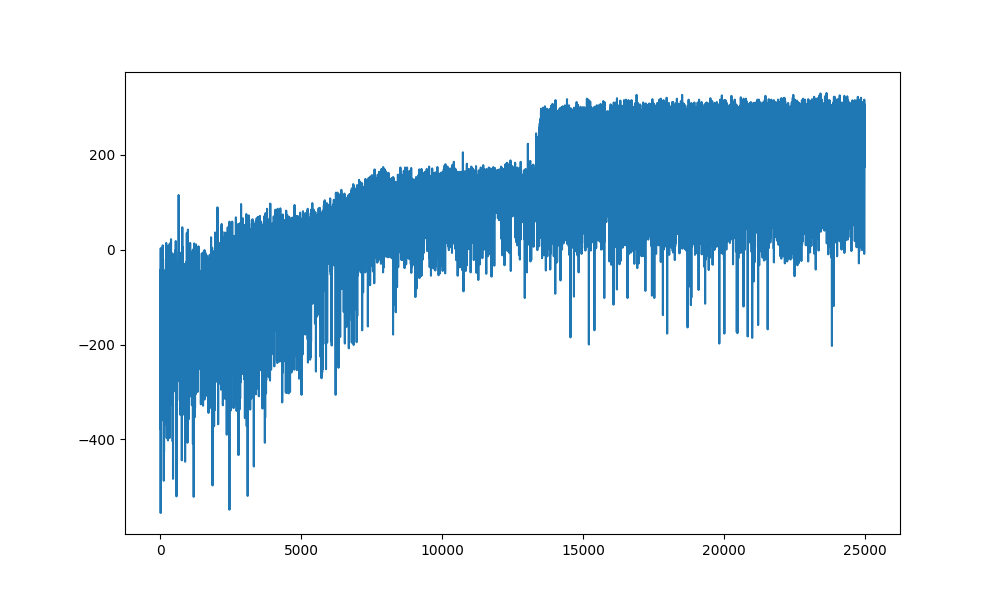
Training curve showing gradual improvement as agent learns landing behavior
Training Progress:
- • Initial: Highly negative rewards (crashes)
- • Mid-training: Gradual improvement as agent explores
- • Final: Moderate stability with successful landings
REINFORCE vs DQN on LunarLander
- • DQN: Faster convergence (~700 episodes), higher final performance (250+)
- • REINFORCE: Slower (5000+ episodes), more variance, but simpler implementation
- • Why: REINFORCE uses full episode returns (high variance) while DQN uses TD learning with replay buffer (lower variance)
Key Takeaways
- ✅ REINFORCE works but requires many more episodes than DQN
- ✅ High variance from Monte Carlo returns slows learning
- ✅ On-policy nature means no experience replay benefit
- ✅ Future improvement: Add baseline (A2C) to reduce variance