Recommender System
Late 2024 — Collaborative Filtering with Alternating Least Squares
Abstract
This project presents the development of a collaborative filtering-based recommender system using Alternating Least Squares (ALS), with latent factor embeddings for users and movies alongside their biases. We address the cold start problem and improve recommendation accuracy by incorporating feature embeddings for movie genres. The implementation uses an efficient algorithm optimized with Numba JIT compilation, reducing training time from 15 minutes to 13 seconds per epoch on the 32M dataset. The final model achieves 0.77 RMSE on MovieLens-32M.
Problem Statement
In streaming and digital content, movie-viewing patterns follow a power law distribution. A handful of popular movies attract the majority of views, while lesser-known films receive minimal engagement. Without personalized recommendations, users face limited diversity—primarily seeing widely viewed content rather than films suited to their specific tastes.
The goal is to develop a system that models user-movie interactions and provides recommendations tailored to individual preferences, giving more exposure to long-tail content.
Dataset Analysis
Experiments used MovieLens datasets: 100K for development, and 25M/32M for final training. The 32M dataset contains 32,000,204 ratings across 87,585 movies.
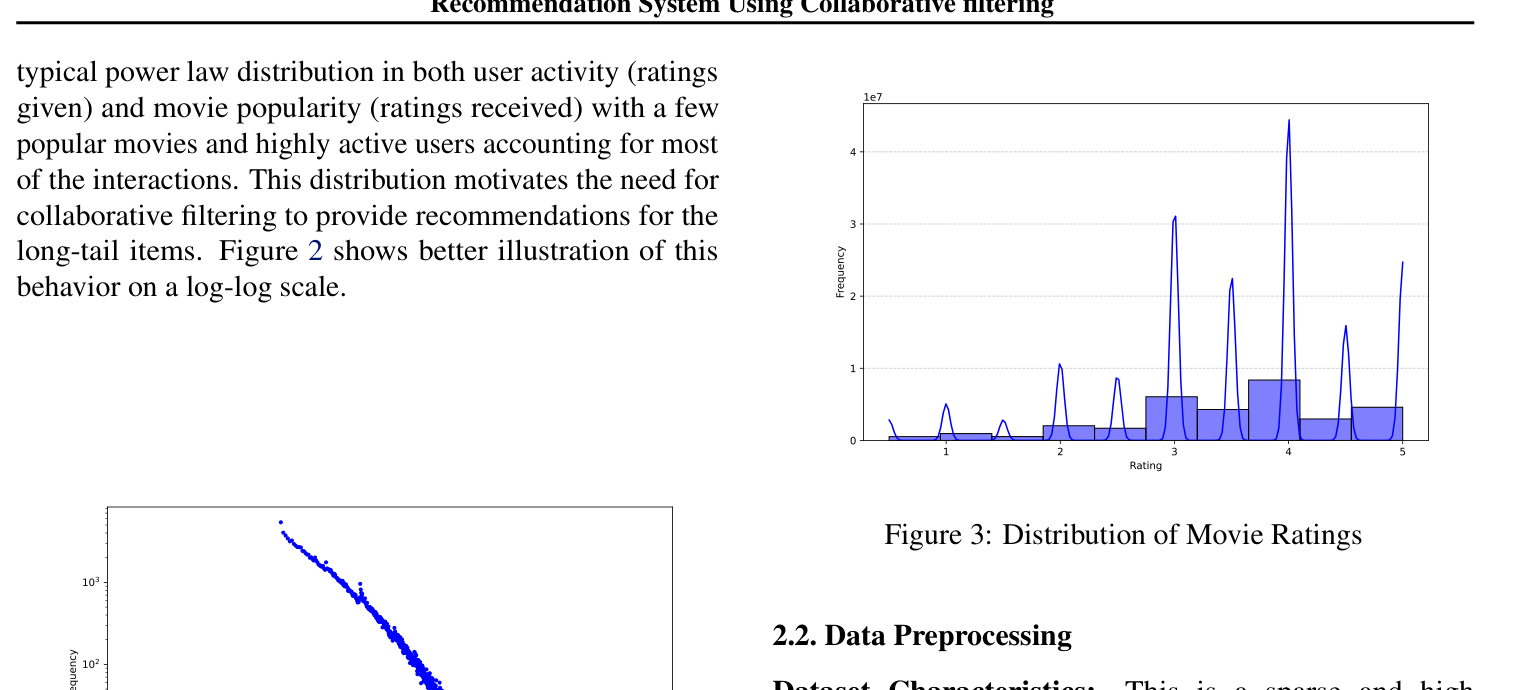
Power law distribution in user activity and movie popularity (log-log scale)
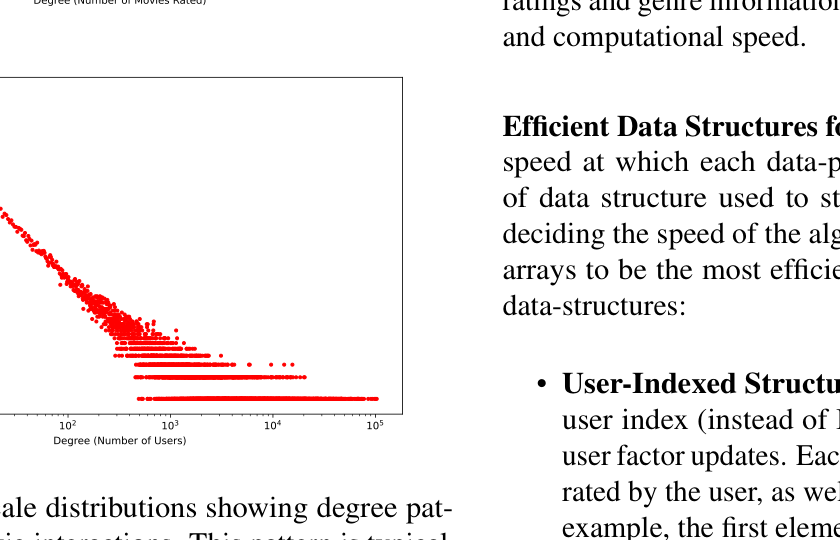
Rating distribution showing bias toward higher ratings (4-5 stars)
Key Insight: The power law distribution motivates collaborative filtering—we need to provide recommendations for the "long tail" of less popular items that users might enjoy.
Methodology
Matrix Factorization with ALS
The core idea is to decompose the sparse user-item rating matrix into lower-dimensional latent factors:
Where U = user embeddings, V = item embeddings, bu = user biases, bi = item biases
Objective Function
The regularized ALS objective minimizes reconstruction error while preventing overfitting:
L(U,V) = (λ/2) Σm,n (rmn - umTvn)² + (τ/2)(Σ||um||² + Σ||vn||²)
Three Models Implemented
Bias-Only ALS
Captures global trends using only user and item biases. Converges in 2-3 epochs.
Latent Factors + Bias
Adds user/movie embeddings (dim=30). Achieves 0.77 RMSE on 32M.
+ Genre Features
Incorporates genre embeddings to address cold start for new movies.
Implementation Highlights
⚡ Performance Optimization
Using Numba JIT compilation with optimized NumPy operations:
Data Structures
- • User-indexed arrays for efficient factor updates
- • Movie-indexed arrays for item factor updates
- • ID-to-index dictionaries for O(1) lookup
- • NumPy object arrays for variable-length data
Hyperparameters (32M)
- • Latent dimensions: 30
- • λ (regularization): 1.0
- • γ (learning rate): 0.001
- • τ (factor regularization): 10
- • Epochs: 100
Results
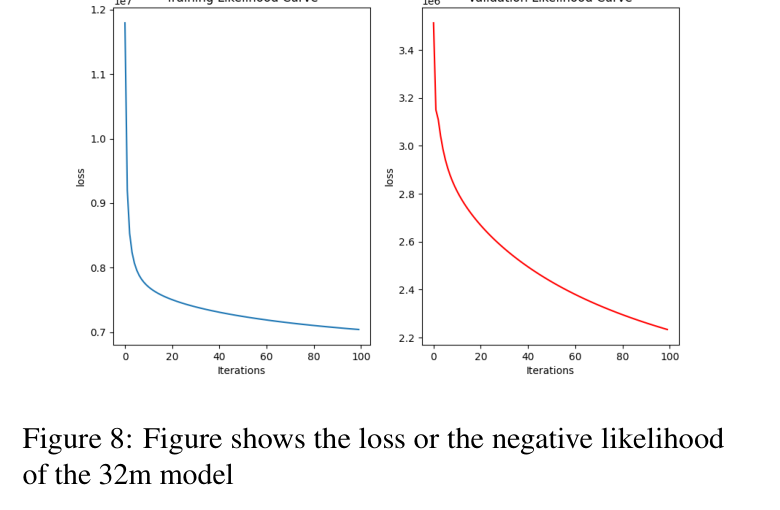
Training Curves
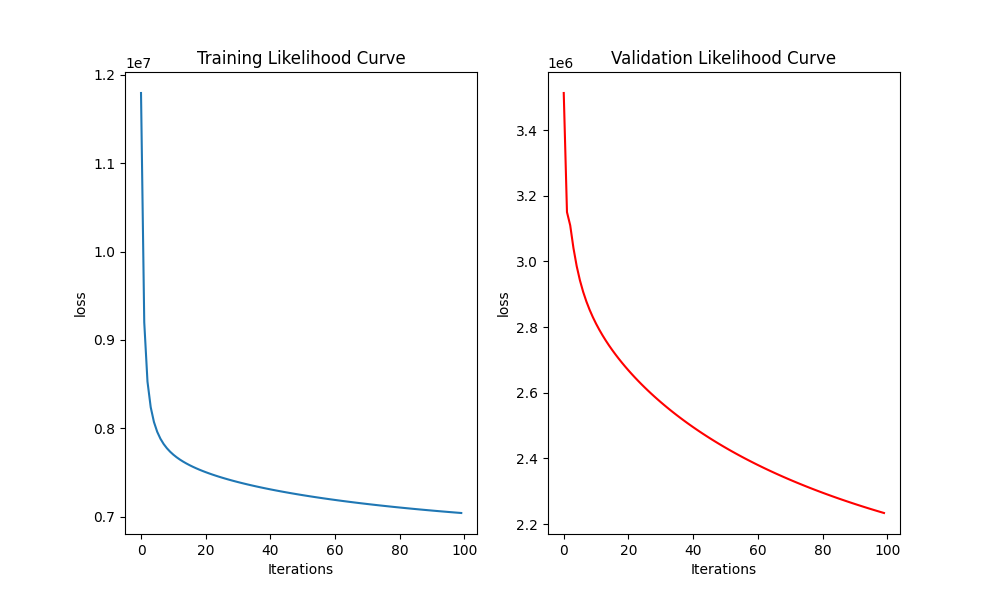
Negative log-likelihood decreasing during training (32M dataset)
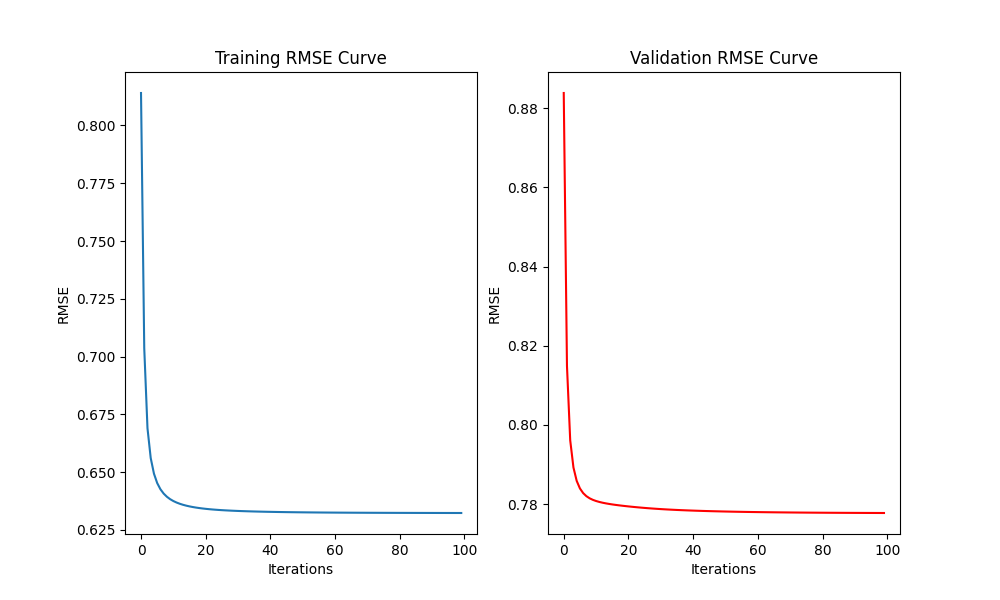
RMSE convergence on training and validation sets
Bias-Only Model (Baseline)

Bias-only model converges in 2-3 epochs
RMSE plateau around 0.85 (bias-only baseline)
Qualitative Evaluation
To validate the model qualitatively, I created dummy users who rated only one movie and examined the top recommendations:
🎬 User liked "Toy Story"
Top 5 Recommendations:
- 1. Toy Story 2 (1999)
- 2. Monsters, Inc. (2001)
- 3. Finding Nemo (2003)
- 4. Toy Story 3 (2010)
- 5. The Incredibles (2004)
✓ All animated family films — makes sense!
🔪 User liked "Saw"
Top 5 Recommendations:
- 1. Saw II (2005)
- 2. Saw III (2006)
- 3. The Ring (2002)
- 4. Saw IV (2007)
- 5. Scream (1996)
✓ All horror/thriller films — captures the genre well!
Key Takeaways
- ✅ Matrix factorization effectively captures latent user preferences
- ✅ ALS is efficient for large sparse matrices with closed-form updates
- ✅ Biases capture systematic tendencies (some users rate higher, some movies are universally liked)
- ✅ Numba JIT provides massive speedups for iterative algorithms
- ✅ Genre features help address the cold start problem for new items
- ✅ Latent dimensions of 25-30 balance expressiveness vs. overfitting